Uncertainty-Aware Attention Mechanism for Pneumonia Detection Using Chest X-Rays
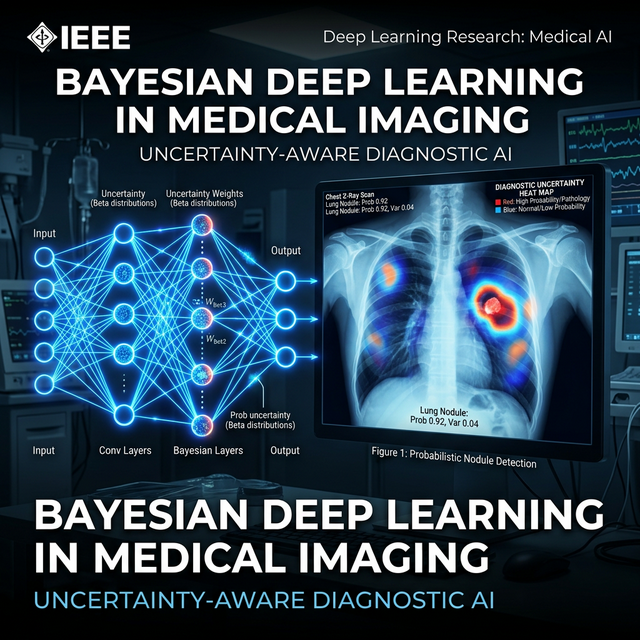
Pneumonia is responsible for over 700,000 deaths per year in children under five. Deep learning models can match human accuracy on chest X-ray diagnosis, but most output binary decisions without explaining why or reporting how confident they are. My research accepted at IEEE AIC 2026 introduces a framework combining dual attention mechanisms (channel + spatial) with Monte Carlo Dropout uncertainty estimation to bridge this clinical trust gap.
Research & Institution
This research was conducted by Rugved Chandekar at the Department of Information Technology, Government College of Engineering, Chhatrapati Sambhajinagar.
Key Research Innovations
Most prior medical AI papers either measure uncertainty or use attention — my work evaluates the joint integration of dual attention (channel and spatial) with Monte Carlo Dropout for pediatric chest X-ray classification.
- Channel + Spatial Attention: Channel attention re-weights feature channels, while spatial attention highlights lung regions and dims background artifacts.
- Monte Carlo Dropout Triage: By running inference across multiple stochastic passes per image, variance serves as a confidence metric. Setting an uncertainty threshold at the 95th percentile flags doubtful cases for human radiologist review.
- Visual Explainability: Grad-CAM heatmaps verify that activations focus on actual lung opacities rather than irrelevant image areas.
Performance Summary
| Metric | Proposed Model |
|---|---|
| Accuracy | 97.18% (+3.51% over baseline) |
| Sensitivity (Recall) | 96.73% (+4.10% over baseline) |
| Specificity | 98.42% |
| F1-Score | 98.04% |
| ROC-AUC | 99.75% |
Clinical Flagging Concentration: Flagging just 5.8% of test cases concentrated 43% of all actual model errors — bringing the effective false-negative rate down from 3.27% to 1.86%.
Interested in uncertainty estimation, explainable AI, or clinical AI integration? Let's connect.
Contact Researcher