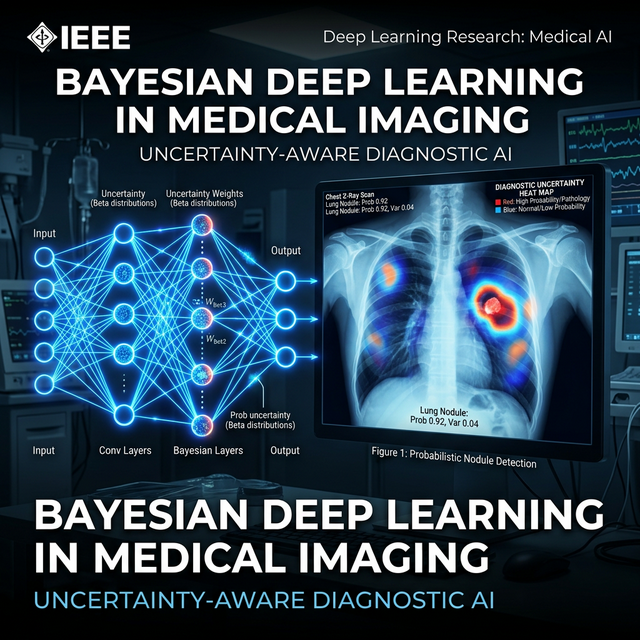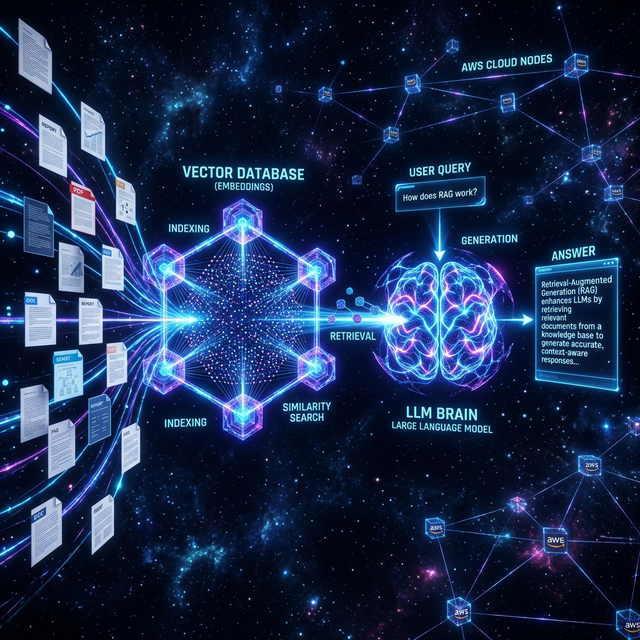
RAG Pipelines: From Theory to Production on AWS
RAG is the difference between an LLM that hallucinates and one that answers with your actual data. Here's the complete production architecture I built on AWS — semantic search, vector storage, LLM generation, and all the edge cases that tutorials skip.
What RAG Actually Is (Beyond the Buzzword)
Retrieval-Augmented Generation = retrieve relevant context from your data → augment the LLM prompt with it → generate a grounded response. It prevents hallucination by giving the model real information instead of asking it to remember things.
The three-step flow:
Query → [Retrieval] → Relevant Chunks → [LLM] → Grounded Answer
(OpenSearch) (Bedrock)The Indexing Pipeline (Offline)
Before anyone can query, you need to index your documents. My pipeline:
- Document loading — Parse PDFs, DOCX, plain text via LangChain document loaders
- Chunking — Split into 512-token overlapping chunks (128-token overlap to preserve context across boundaries)
- Embedding — Each chunk embedded using Amazon Titan Embeddings (1536-dim vectors)
- Indexing — Vectors stored in Amazon OpenSearch Serverless k-NN index
from langchain.text_splitter import RecursiveCharacterTextSplitter
import boto3
import json
bedrock = boto3.client('bedrock-runtime')
def embed(text):
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v1',
body=json.dumps({'inputText': text})
)
return json.loads(response['body'].read())['embedding']
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=128
)
chunks = splitter.split_text(document_text)
for chunk in chunks:
vector = embed(chunk)
opensearch_client.index(index='docs', body={
'text': chunk,
'embedding': vector
})The Query Pipeline (Online / Real-Time)
When a user asks a question:
- Embed the query using the same Titan model
- K-NN search in OpenSearch — retrieve top-5 semantic matches
- Build a prompt with retrieved chunks as context
- Call Claude via Amazon Bedrock — stream the response back
def answer_query(query: str) -> str:
# Step 1: Embed the query
query_vector = embed(query)
# Step 2: Semantic search
results = opensearch_client.search(
index='docs',
body={
'knn': {'field': 'embedding', 'query_vector': query_vector, 'k': 5}
}
)
context = "\n\n".join([r['_source']['text'] for r in results['hits']['hits']])
# Step 3: LLM generation with context
prompt = f"""Answer based only on the context below:
Context:
{context}
Question: {query}
Answer:"""
response = bedrock.invoke_model(
modelId='anthropic.claude-3-sonnet-20240229-v1:0',
body=json.dumps({'prompt': prompt, 'max_tokens': 1024})
)
return json.loads(response['body'].read())['completion']The AWS Deployment Stack
- Amazon ECS (Fargate) — Flask API deployed as a containerized service, auto-scaling
- Amazon OpenSearch Serverless — Managed vector database, scales to zero when idle
- Amazon Bedrock — Claude 3 Sonnet for generation, Titan for embeddings
- ECR — Docker image registry for the Flask app
- ALB — Application Load Balancer in front of ECS for HTTPS termination
The Token Cost Problem (And How We Solved It)
At scale, the biggest RAG cost is tokens — every query sends context that can be 2,000+ tokens. At my internship, we reduced token usage by ~99% through:
- Hierarchical retrieval — Retrieve document summaries first, only fetch full chunks when needed
- Caching embeddings — Same query twice? Return cached vector, skip re-embedding
- Prompt compression — Use a small model to compress retrieved context before sending to Claude
Need a RAG system integrated into your product? From document Q&A to AI search — I build this stack.
Start a Project